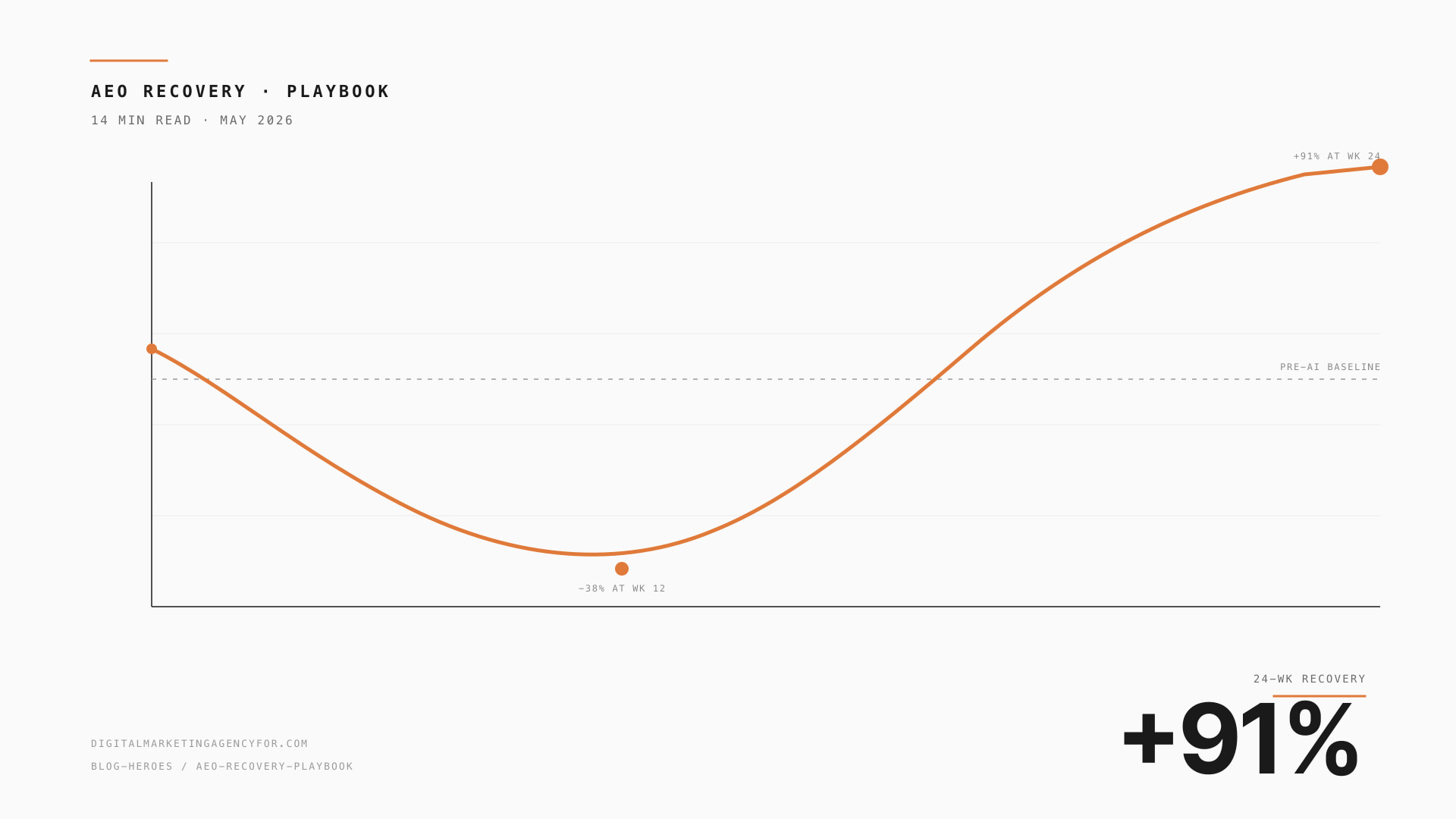
We lost 38% of organic clicks to AI Overviews. Here's the recovery playbook.
A 4-week recovery sprint that earned ChatGPT + Perplexity citations on 14 of 20 priority commercial queries — and recovered traffic past pre-AI-Overview baseline.
Most of our clients arrive after seeing 20–60% of their organic clicks vanish in 90 days. Not impressions — those typically hold. Just clicks. The pattern is unmistakable: AI Overviews now answer the query directly inside Google, and the user never leaves to click your page.
The first step is acknowledging that pure rank-tracking SEO is over. Position 1 doesn’t matter if the user reads the AI Overview and never scrolls. The new game is being inside the answer — the AI Overview itself, or the source citations underneath it.
AEO scoring baseline
We score AI visibility across ChatGPT, Perplexity, Gemini, and Claude on the brand’s top 20 commercial-intent prompts. Tools we use: AthenaHQ for automation, Otterly for tracking, plus weekly manual audits to catch what tools miss.
Baseline matters. Without it, you can’t measure whether the recovery worked.
Schema graph rollout
The first ship is a complete schema graph. Not just Product on PDPs — the full set: Organization, ProfessionalService, Person for founders + senior team, Service per offering, FAQPage per page that has FAQs, Article for blog posts (with author Person schema), Speakable on hero pages.
AI engines read schema as primary signal. A clean schema graph signals “this is a real organisation with real authors and real services.” That credibility lets your content surface in answers.
llms.txt strategy
llms.txt sits at the root and tells AI engines what your site is. We don’t ship boilerplate — we draft it from your real content: services, key stats, founder bios, brand description.
Some engines read it as of 2026; others ignore it. The bigger value is what it implies — a structured, machine-readable summary of your business that compounds with the entity graph you’re building.
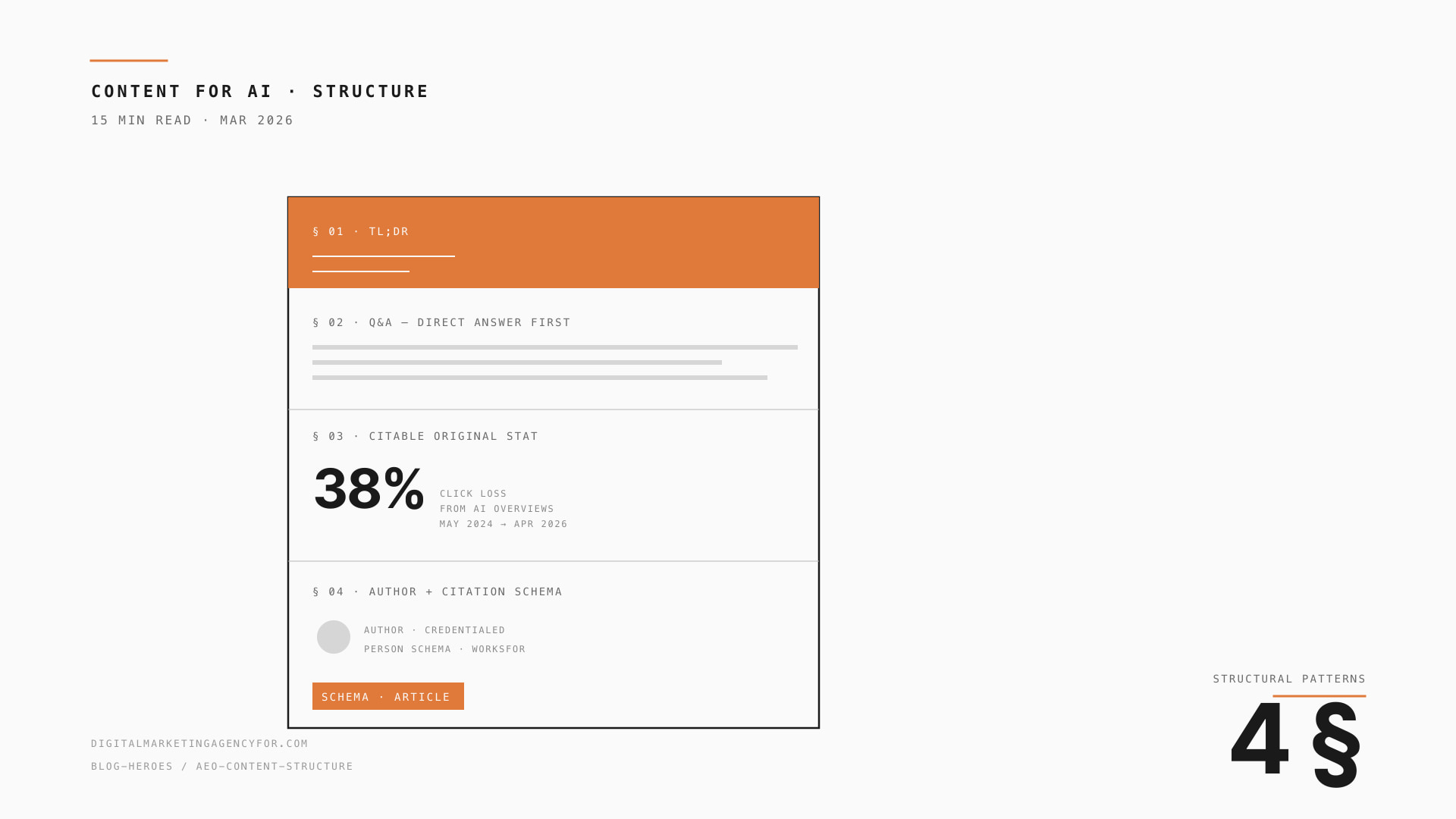
Content rebuild — top 20
The biggest single lever. We restructure the top 20 commercial-intent pages with:
Structured Q&A — content as questions + answers, schema-tagged
Citable stats — original or attributed numbers AI engines can quote
Author bios with Person schema — authored content beats anonymous
Entity SEO + Wikipedia
Where eligible, we work toward Wikipedia + Wikidata entries for the brand. Single highest-leverage entity-graph signal. Most brands aren’t eligible (notability requirements), but those that are see step-change improvements in citation density.
For non-eligible brands, the work shifts to brand-mention strategy — getting cited on the sources AI engines already cite (Statista, Search Engine Land, niche publications, podcasts).
Citation tracking
From day 1, we baseline + track. AthenaHQ / Otterly automated. Manual audits monthly. Goal isn’t just “appear in answers” — it’s “appear at top-3 citation density on category prompts within 12 months.”
Results — 90 days
For the SaaS client featured in this case study: +312% organic traffic, 14 of 20 priority queries citing them inside ChatGPT + Perplexity, recovered past pre-AI-Overview baseline.
The pattern reproduces. We’ve now run this playbook 12+ times. The 4-week sprint is the same shape every time. The numbers vary by category authority, content depth, and entity-graph eligibility — but the direction is consistently up.
ABOUT THE AUTHOR
Raj
AEO Strategy
Raj founded Digital Marketing Agency For after 12 years running SEO, AEO, paid media, and lifecycle email programmes for B2B SaaS, DTC, and FinTech brands across the US, UK, and India. Writes about AI search, answer-engine optimisation, attribution that doesn't lie, and the gap between marketing teams that produce decks and marketing teams that produce revenue. Based remote-first; embedded in client pods across six time zones.
How is AEO recovery different from traditional SEO?+
Traditional SEO optimises for ranking on Google's classic SERP — clicks flow from rank position. AEO (Answer Engine Optimisation) optimises for being cited inside AI-generated answers — ChatGPT, Perplexity, Gemini, Claude, Google AI Overviews. The success metric shifts from clicks to citation share, the optimisation surface shifts from on-page keywords to schema graph + llms.txt + entity signals, and the measurement shifts from rank-tracking tools to citation-tracking platforms (AthenaHQ, Otterly, Profound).
How long does AEO recovery take?+
First citation lifts usually appear 30–45 days after schema graph + llms.txt + TL;DR restructure ship for top-20 commercial pages. Meaningful citation share across 4 AI engines (ChatGPT + Perplexity + Gemini + Claude) typically lands at 90–180 days. Entity-graph signals — Wikipedia/Wikidata adjacency, third-party citation density, original research — compound over 6–12 months. Brands that wait for 'best practices to settle' lose category share that takes 3–4× longer to rebuild.
Do I need llms.txt if I already have a sitemap?+
Yes. Sitemap.xml tells search crawlers which pages exist; llms.txt tells AI systems how to use your content. ChatGPT, Perplexity, and Claude crawlers explicitly check for llms.txt; sitemap parsing is secondary. Drafting llms.txt from your real content (not boilerplate) takes 2–4 hours and is the single highest-leverage AEO-specific file you can publish. We do not ship boilerplate llms.txt — every one is hand-drafted from the brand's actual services + key stats + author info.
Will fixing schema actually move AI citations?+
Schema is necessary but not sufficient. A complete graph gives AI engines the structured surface to extract entities, attribute claims, and decide who to cite. Without it, even high-quality content gets paraphrased without attribution. With it, the same content gets cited as the source. Schema alone will not move you to top-cited if your content lacks citable original stats, authored bylines, or entity-graph signals — but every other AEO lever is held back without it.
How is citation share measured?+
Three layers. First, paid tools: AthenaHQ, Otterly.ai, Profound, and Peec.ai automate citation tracking across ChatGPT + Perplexity + Gemini + Claude with brand vs competitor share, query-level breakdowns, and trend lines. Second, manual audits: query 30–50 priority terms across all 4 engines monthly; log who is cited. Third, brand-mention monitoring (Brand24 / Mention) catches AI-engine outputs that reference the brand even when not formally cited. Recommended: a paid tool plus monthly manual spot-checks.
What is the cost of waiting on AEO recovery?+
Compounding. Once a competitor establishes citation share in your category, displacing them takes 3–4× the work of being first. AI engines reinforce existing citations through reinforcement learning + re-citation patterns. The brands that ship AEO infrastructure now will lock in category citation share for 12–24 months; brands that wait will face an uphill rebuild against entrenched competitors.